如若轉(zhuǎn)載,請注明出處:http://www.sjj4.cn/product/27.html
更新時(shí)間:2026-03-07 03:56:38
臺(tái)州玉環(huán)互聯(lián)網(wǎng)推廣 助企科技公司 互聯(lián)網(wǎng)推廣公司圖片
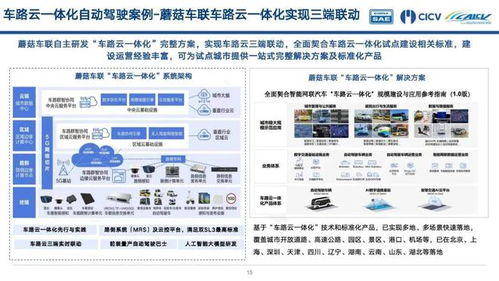
基于多模態(tài)大模型和超大算力,車路云一體化進(jìn)入3.0階段
CyeeCare葆齡酶在亦奈爾商城正式上線,全面開啟新零售時(shí)代!
海克斯康榮獲“山東省智能工廠”和“山東省智能制造系統(tǒng)解決方案供應(yīng)商”雙料榮譽(yù)稱號
科力遠(yuǎn)CHS佛山工廠正式投產(chǎn) 總規(guī)劃100萬臺(tái)/套產(chǎn)能
女子加工廠:女性的創(chuàng)業(yè)夢工廠,共創(chuàng)輝煌未來!
工信部 建材工業(yè)鼓勵(lì)推廣應(yīng)用的技術(shù)和產(chǎn)品目錄 2016 2017年本
上海市節(jié)能低碳技術(shù)產(chǎn)品推廣目錄 2018年本 發(fā)布 包括六項(xiàng)發(fā)電行業(yè)技術(shù)
智能化反滲透“RO 110”系統(tǒng)問世
西工大數(shù)字孿生技術(shù)叢書出版 助力我國航空發(fā)動(dòng)機(jī)數(shù)智化技術(shù)推廣應(yīng)用
電話:18765773087
地址:山東省濰坊市昌邑市奎聚街道城里東街南側(cè)
Copyright © 2026 www.sjj4.cn 技術(shù)推廣 昌邑市宏碩網(wǎng)絡(luò)科技有限公司 技術(shù)推廣 版權(quán)所有 Sitemap